





Как использовать Redis Cluster для кэширования
В этом посте мы рассмотрим, как мы можем использовать Redis в качестве провайдера кеша для нашего приложения, и по мере дальнейшего изучения мы увидим, как кластер Redis может обеспечить нам большую масштабируемость и надежность
Что такое Редис?
Redis - это хранилище ключей и значений. Грубо говоря, оно работает точно так же, как база данных, но хранит свои данные в памяти, а это означает, что операции чтения и записи выполняются на несколько порядков быстрее по сравнению с реляционными базами данных, такими как MySQL и PostgreSQL. Важно отметить, что Redis не заменяет реляционную базу данных. У него есть свои варианты использования, и мы рассмотрим некоторые из них в этом посте.
Для получения дополнительной информации о Redis можете посетить их сайт. Там вы найдете хорошую документацию и информацию о том, как работать с Redis. Тем не менее, в этом посте мы создадим демонстрацию и будем использовать интересную настройку с использованием Docker и docker-compose, которая запустит и настроит для вас весь кластер Redis. Единственное что вам нужно это Docker.
Кстати, если вы уже знакомы с Redis и просто ищете способ развернуть полностью настроенный кластер Redis с помощью Docker, вот репозиторий Github. Просто клонируйте репозиторий, зайдите в свой терминал, запустите, docker-compose up и все будет готово.

Использование Redis для кэширования
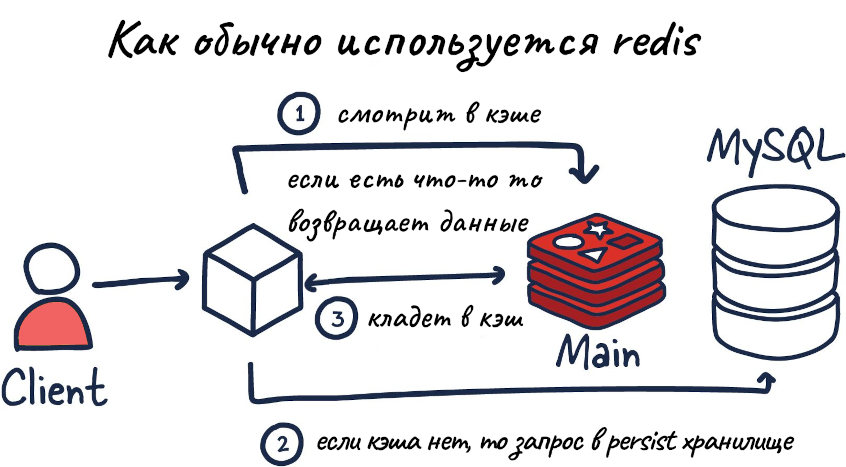
Всякий раз, когда нам нужен быстрый доступ к каким-либо данным, нам нужно подумать о способах хранения этих данных как можно ближе к прикладному уровню. Если объем данных достаточно мал, рекомендуется хранить эти данные в локальной памяти, чтобы иметь мгновенный доступ. Но когда мы говорим о веб-приложениях, особенно о тех, которые не сохраняют состояние и потенциально могут работать на нескольких серверах, мы не можем гарантировать, что нужные нам данные будут присутствовать, а также убедиться, что другие серверы в вашем кластере имеют быстрый доступ к эти же данные.
Вот где базы данных удобны. Мы можем записывать эти данные в центральное место, а другие серверы могут получать эти данные, когда им это нужно. Проблема с некоторыми базами данных заключается в том, что если вам действительно нужен молниеносно быстрый доступ, некоторые из них не смогут обеспечить это со скоростью пули. Redis обычно является базой данных, к которой нужно обращаться, когда вам нужен быстрый и надежный доступ к определенным битам данных. Он также предоставляет нам способы установить политики истечения срока действия для этих данных, чтобы они автоматически удалялись по истечении срока их действия.
Redis обычно является хорошим выбором для хранения:
- Сессии пользователей
- Токены аутентификации
- Лимиттеры - Счетчики ограничения скорости/доступа
Redis ни в коем случае не ограничивается описанными выше вариантами использования, но они хорошо подходят, когда вам нужен быстрый доступ к данным, чаще всего при каждом запросе, поступающем через ваши серверы.
Для чего нужно использовать Redis кластер?
Обычно когда нагрузка на приложение небольшая - принято начинать с одного экземпляра сервера, возможно, подключенного к серверу базы данных, что может занять некоторое дополнительное время. Но когда вам нужно масштабировать приложение в разных странах, а иногда и на разных континентах, это, вероятно, означает, что ваше приложение должно быть доступно 24 часа в сутки, 7 дней в неделю. А надежность и устойчивость должны быть встроены в ваше приложение.
Вам нужно начать думать о том, что происходит, когда один из ваших серверов баз данных выходит из строя либо из-за проблемы в сети, либо из-за неисправного оборудования. Если у вас есть только один экземпляр, то скорее всего приложение будет недоступно некоторое время. И потребуется время снова запустить его в работу.
Если ваше приложение критически важно, в частности те же интернет-магазины, вы не можете позволить себе быть в оффлайн режиме в течение нескольких часов. Некоторые приложения не могут находиться в автономном режиме даже несколько минут. Именно здесь кластер с репликами может спасти вас, когда возникает подобная проблема.
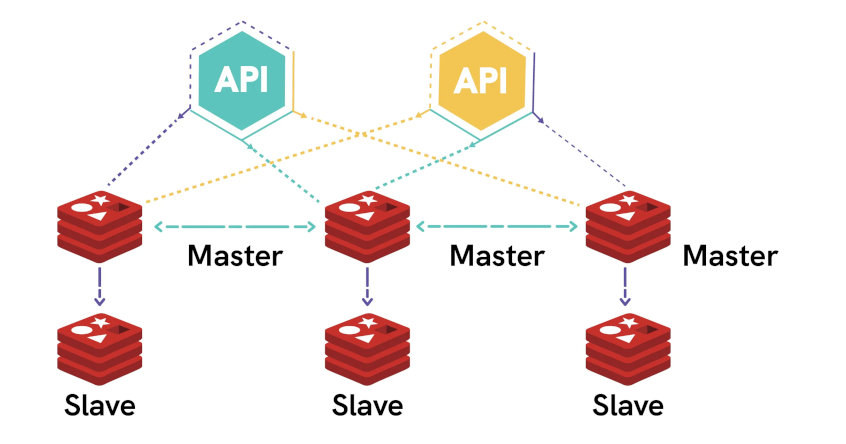
Кластер Redis обеспечивает автоматический обмен данными между несколькими экземплярами Redis, что обеспечивает более высокий уровень надежности и доступности. Если в одном из этих экземпляров произойдет какой-либо сбой, другие узлы по-прежнему смогут нормально обслуживать контент для вашего приложения.
Так же кластеризация Redis на одном сервере позволит поднять несколько экземпляров Redis и решить проблему его однопоточности, в которую иногда упирается высоконагруженое приложение.
Запуск кластера Redis
Недавно мы уперлись в потолок нашего одного экземпляра Редиса, т.к. интернет-магазин, а помимо него еще и внутри корпоративная система слишком усердно "ддосили" редис и одного экземпляра стало уже мало, поэтому было принято решение перейти на кластер с несколькими сегментами, включая несколько реплик. Кстати до кластера мы попробовали форк KeyDB, который показал себя не с лучшей стороны в плане стабильности работы, после чего решили вернуться к редису, последней версии с несколькими инстансами.
Чтобы было проще поднять и убедиться, что мы можем поддерживать кластер Redis во время разработки, была создана установка нескольких контейнеров Redis и автоматическое подключение друг к другу для формирования кластера.
Вся настройка готова для вас в этом репозитории Github https://github.com/sinbadxiii/docker-redis-cluster, поэтому вам не нужно беспокоиться о создании чего-либо с нуля. Вы можете клонировать его и попробовать запустить, пока мы будет обсуждать пост дальше.
Создание docker-compose.yml для Redis кластер
По сути, конечно, мы будем использовать несколько одинаковых сервисов redis_# последних образов redis-latest. И только последний специальный контейнер redis_cluster будет отдавать команды Redis таким образом, чтобы он мог сформировать кластер:
Итак содержимое файла будем таким:
version: '3.3'
networks:
network_redis_cluster:
driver: bridge
ipam:
driver: default
config:
- subnet: 173.18.0.0/16
volumes:
redis_1_data: {}
redis_2_data: {}
redis_3_data: {}
redis_4_data: {}
redis_5_data: {}
redis_6_data: {}
services:
redis_1:
image: redis:latest
restart: always
container_name: redis_1
sysctls:
- net.core.somaxconn=65536
ports:
- "127.0.0.1:6381:6381"
- "127.0.0.1:16381:16381"
networks:
network_redis_cluster:
ipv4_address: 173.18.0.11
command: "redis-server /usr/local/etc/redis/redis.conf"
volumes:
- redis_1_data:/data
- ./redis_1/redis.conf:/usr/local/etc/redis/redis.conf
redis_2:
image: redis:latest
restart: always
container_name: redis_2
sysctls:
- net.core.somaxconn=65536
networks:
network_redis_cluster:
ipv4_address: 173.18.0.12
ports:
- "127.0.0.1:6382:6382"
- "127.0.0.1:16382:16382"
volumes:
- redis_2_data:/data
- ./redis_2/redis.conf:/usr/local/etc/redis/redis.conf
command: "redis-server /usr/local/etc/redis/redis.conf"
redis_3:
image: redis:latest
restart: always
container_name: redis_3
sysctls:
- net.core.somaxconn=65536
networks:
network_redis_cluster:
ipv4_address: 173.18.0.13
ports:
- "127.0.0.1:6383:6383"
- "127.0.0.1:16383:16383"
volumes:
- redis_3_data:/data
- ./redis_3/redis.conf:/usr/local/etc/redis/redis.conf
command: "redis-server /usr/local/etc/redis/redis.conf"
redis_4:
image: redis:latest
restart: always
container_name: redis_4
sysctls:
- net.core.somaxconn=65536
networks:
network_redis_cluster:
ipv4_address: 173.18.0.14
ports:
- "127.0.0.1:6384:6384"
- "127.0.0.1:16384:16384"
volumes:
- redis_4_data:/data
- ./redis_4/redis.conf:/usr/local/etc/redis/redis.conf
command: "redis-server /usr/local/etc/redis/redis.conf"
redis_5:
image: redis:latest
restart: always
container_name: redis_5
sysctls:
- net.core.somaxconn=65536
networks:
network_redis_cluster:
ipv4_address: 173.18.0.15
ports:
- "127.0.0.1:6385:6385"
- "127.0.0.1:16385:16385"
volumes:
- redis_5_data:/data
- ./redis_5/redis.conf:/usr/local/etc/redis/redis.conf
command: "redis-server /usr/local/etc/redis/redis.conf"
redis_6:
image: redis:latest
restart: always
container_name: redis_6
sysctls:
- net.core.somaxconn=65536
networks:
network_redis_cluster:
ipv4_address: 173.18.0.16
ports:
- "127.0.0.1:6386:6386"
- "127.0.0.1:16386:16386"
volumes:
- redis_6_data:/data
- ./redis_6/redis.conf:/usr/local/etc/redis/redis.conf
command: "redis-server /usr/local/etc/redis/redis.conf"
redis_cluster:
image: redis:latest
container_name: redis_cluster
sysctls:
- net.core.somaxconn=65536
networks:
network_redis_cluster:
ipv4_address: 173.18.0.17
tty: true
command: "redis-cli --cluster create 173.18.0.11:6381 173.18.0.12:6382 173.18.0.13:6383 173.18.0.14:6384 173.18.0.15:6385 173.18.0.16:6386 --cluster-replicas 1 --cluster-yes"
depends_on:
- redis_1
- redis_2
- redis_3
- redis_4
- redis_5
- redis_61. Создает несколько экземпляров Redis
2. Настраивает их IP-адреса и порты так, чтобы они соответствовали тем, которые мы сможем использовать.
3. Скопирует конфиг файл redis.conf, чтобы они могли действовать как кластер
4. Создает контейнер инициатора кластера, который необходим только для выполнения нашей команды и подключения к кластеру.
Основной секрет здесь кроется в команде redis-cli:
redis-cli --cluster create 173.18.0.11:6381 173.18.0.12:6382 173.18.0.13:6383 173.18.0.14:6384 173.18.0.15:6385 173.18.0.16:6386 --cluster-replicas 1 --cluster-yesЭта команда создает кластер и указывает на конкретные экземпляры Redis, которые будут доступны при запуске этого скрипта, здесь мы используем жестко закодированные IP-адреса, которые позже будут предоставлены нашим файлом docker-compose.yml.
Этот кластер состоит из 3 сегментов. В каждом сегменте есть главный узел, отвечающий за все операции записи, а также узел-реплика, содержащий копию данных. Шард кластера Redis может иметь до 500 реплик. Узел-реплика может стать главным узлом, если текущий главный узел становится недоступным.
Теперь обратите внимание, что внутри наших redis папок у нас также есть файлы с именем redis.conf. Позже этот файл будет скопирован в каждый контейнер Redis, чтобы они могли указать экземпляру Redis работать как часть кластера. Давайте посмотрим на его содержимое:
port 6381
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 3000
appendonly yes
tcp-keepalive 0
#save 900 1
#save 300 10
#save 60 10000
tcp-backlog 65536Там не так уж и много чего происходит. Важен параметр cluster-enabled yes, что позволяет нашему экземпляру Redis действовать как часть кластера.
Теперь, когда мы узнали все детали файла, давайте попробуем запустить все это. Перейдите в свой терминал и выполните:
docker-compose up -dНу и в принципе все. Если все прошло удачно, как на гифке в начале поста, то вы уже можете приступать к использованию кластера редис в своем приложении.
Чтобы подключиться к Redis из вашего приложения, вам понадобится библиотека, которая может сделать это за вас. Для каждого языка есть своя реализация подключения к кластеру, т.к. мы используем predis то вот пример для PHP:
$client = new \Predis\Client(
[["host" => "127.0.0.1", "port" => 6381],
["host" => "127.0.0.1", "port" => 6382],
["host" => "127.0.0.1", "port" => 6383],
["host" => "127.0.0.1","port" => 6384],
["host" => "127.0.0.1", "port" => 6385],
["host" => "127.0.0.1", "port" => 6386]],
['cluster' => 'redis']
);Для Golang:
import "github.com/redis/go-redis/v9"
rdb := redis.NewClusterClient(&redis.ClusterOptions{
Addrs: []string{":6381", ":6382", ":6383", ":6384", ":6385", ":6386"},
// To route commands by latency or randomly, enable one of the following.
//RouteByLatency: true,
//RouteRandomly: true,
})
Python:
>>> from rediscluster import RedisCluster
>>> # Requires at least one node for cluster discovery. Multiple nodes is recommended.
>>> startup_nodes = [{"host": "127.0.0.1", "port": "6381"}, {"host": "127.0.0.1", "port": "6382"}] # ... and etc.
>>> rc = RedisCluster(startup_nodes=startup_nodes, decode_responses=True)
>>> rc.set("foo", "bar")
True
>>> print(rc.get("foo"))
'bar'Ну вот в принципе и все, есть пару условий, которые нужно учитывать для работы с редисом в кластере, например вы не можете использовать такие функции как keys и подобные, но и в продакшне не рекомендуется, конечно, это делать. Тот же scan будет куда предпочтительнее.
Кстати если вы посмотрите данные редиса, то можете заметить, что некоторые ключи хранятся в одном главном узле, а другие ключи хранятся в других узлах. Это распределение данных, выполняемое Redis, которое обеспечивает балансировку нагрузки в кластере.
Я надеюсь, что эта установка Docker поможет вам в рабочем процессе разработки так же, как это недавно помогло мне и моей команде. Если у вас есть какие-либо вопросы, пишите в комментариях, т.к. тема достаточно сложная и всегда можно дополнить ее деталями.



Василий Топоров03.04.2025
Вы можете не задавать жестко айпи адреса для контейнеров кластера. Если вы создали docker-compose с сетью типа bridge и сделали ей external: true, то контейнеры внутри кластера будут доступны по именам (redis_1, redis_2, ... redis_9 в вашем случае - можно через name в описании контейнера задать другое имя), и далее его использовать везде как хост:порт для коннекта - redis_1:6381 Для внешней сети они при открытых портах как у вас будут доступны как localhost:6381 (для redis_1). Советую посмотреть https://github.com/bitnami/containers/blob/main/bitnami/redis-cluster/docker-compose.yml (там и документация хорошая).